
{kind=link}
机器之心专栏
机器之心编辑部
日本北海道大学提出 Gromov-Wasserstein Autoencoders(GWAE),将变分自编码器 Variational Autoencoder (VAE) 重写为数据和表示之间的最优传输的灵活表徵学习框架。
学习高维数据的低维表示是无监督学习中的基本任务,因为这种表示简明地捕捉了数据的本质,并且使得执行以低维输入为基础的下游任务成为可能。变分自编码器(VAE)是一种重要的表示学习方法,然而由於其目标控制表示学习仍然是一个具有挑战性的任务。虽然 VAE 的证据下界(ELBO)目标进行了生成建模,但学习表示并不是直接针对该目标的,这需要对表示学习任务进行特定的修改,如解纠缠。这些修改有时会导致模型的隐式和不可取的变化,使得控制表示学习成为一个具有挑战性的任务。
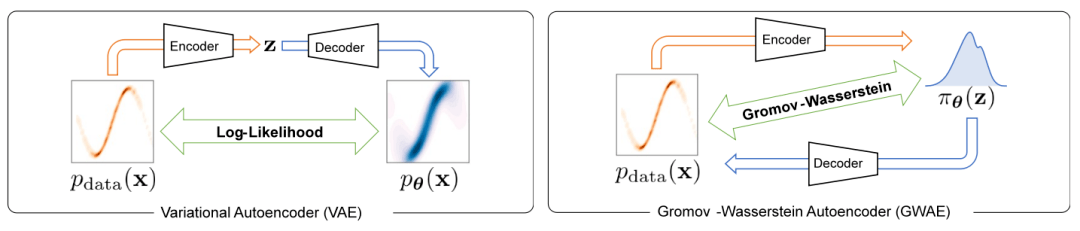
为了解决变分自编码器中的表示学习问题,本文提出了一种称为 Gromov-Wasserstein Autoencoders(GWAE)的新型生成模型。GWAE 提供了一种基於变分自编码器(VAE)模型架构的表示学习新框架。与传统基於 VAE 的表示学习方法针对数据变数的生成建模不同,GWAE 通过数据和潜在变数之间的最优传输获得有益的表示。Gromov-Wasserstein(GW)度量使得在不可比变数之间(例如具有不同维度的变数)进行这种最优传输成为可能,其侧重於所考虑的变数的距离结构。通过用 GW 度量替换 ELBO 目标,GWAE 在数据和潜在空间之间执行比较,直接针对变分自编码器中的表示学习(如图 1)。这种表示学习的表述允许学习到的表示具有特定的被认为有益的属性(例如分解性),这些属性被称为元先验。

图 1 VAE 与 GWAE 的区别
本研究目前已被 ICLR 2023 接受。

方法介绍
数据分布和潜在先验分布之间的GW目标定义如下 :

这种最优传输代价的公式可以衡量不可比空间中分布的不一致性;然而对於连续分布,由於需要对所有耦合进行下确界,计算精确的 GW 值是不切实际的。为了解决这个问题,GWAE 解决了一个松弛的优化问题,以此来估计和最小化 GW 估计量,其梯度可以通过自动微分进行计算。松弛目标是估计的 GW 度量和三个正则化损失的总和,可以在可微编程框架(如 PyTorch)中全部实现。该松弛目标由一个主要损失和三个正则化损失组成,即主要估计的 GW 损失,基於 WAE 的重构损失,合并的充分条件损失以及熵正则化损失。
这个方案还可以灵活地定制先验分布,以将有益的特徵引入到低维表示中。具体而言,该论文引入了三种先验族群,分别是:
神经先验 (NP) 在具有 NP 的 GWAEs 中,使用全连接的神经网路构建先验采样器。该先验分布族群在潜在变数方面做出了更少的假设,适用於一般情况。
因子化神经先验 (FNP)在具有 FNP 的 GWAEs 中,使用本地连接的神经网路构建采样器,其中每个潜在变数的条目独立生成。这种采样器产生一个因子化的先验和一个逐项独立的表示,这是代表性元先验、解纠缠的一种突出方法。
高斯混合先验 (GMP) 在 GMP 中,定义为几个高斯分布的混合物,其采样器可以使用重参数化技巧和 Gumbel-Max 技巧来实现。GMP 允许在表示中假设簇,其中先验的每个高斯组件都预计捕捉一个簇。
实验及结果
该研究对 GWAE 进行了两种主要元先验的经验评估:解纠缠和聚类。
解纠缠 研究使用了 3D Shapes 数据集和 DCI 指标来衡量 GWAE 的解纠缠能力。结果表明,使用 FNP 的 GWAE 能够在单个轴上学习对象色调因素,这表明了 GWAE 的解纠缠能力。定量评估也展示了 GWAE 的解纠缠表现。


聚类 为了评估基於聚类元先验获得的表徵,该研究进行了一项 Out-of-Distribution(OoD)检测。MNIST 数据集被用作 In-Distribution(ID)数据,Omniglot 数据集被用作 OoD 数据。虽然 MNIST 包含手写数字,但 Omniglot 包含不同字母的手写字母。在这个实验中,ID 和 OoD 数据集共享手写图像领域,但它们包含不同的字元。模型在 ID 数据上进行训练,然後使用它们学到的表徵来检测 ID 或 OoD 数据。在 VAE 和 DAGMM 中,用於 OoD 检测的变数是先验的对数似然,而在 GWAE 中,它是 Kantorovich potential。GWAE 的先验是用 GMP 构建的,以捕捉 MNIST 的簇。ROC 曲线显示了模型的 OoD 检测性能,其中所有三个模型都实现了近乎完美的性能;然而,使用 GMP 构建的 GWAE 在曲线下面积(AUC)方面表现最佳。

此外该研究对 GWAE 进行了生成能力的评估。
作为基於自动编码器的生成模型的性能 为了评估 GWAE 在没有特定元先验的情况下对一般情况的处理能力,使用 CelebA 数据集进行了生成性能的评估。实验使用 FID 评估模型的生成性能,使用 PSNR 评估自编码性能。GWAE 使用 NP 获得了第二好的生成性能和最佳的自编码性能,这表明其能够在其模型中捕捉数据分布并在其表示中捕捉数据信息的能力。

总结